Speed Up Read Queries on a Non Indexed Table
SQL — Sympathise how indices work under the hood to speed up your queries
No more waiting for slow queries to finish
![]()
Ever wondered how a database engine can render data for your queries that fast? How information technology can search through many tables, and millions of records in a wink? This article explores how the database engine works nether the hood and sheds light on how to design your tables and indices in the well-nigh optimal way. No more waiting for queries to finish!
As usual we'll kickoff gear up an example , creating some sample data so we have something to work with. So we'll cheque out how the database engine performs without indices. So nosotros'll add indices to speed upward our queries, demonstrating how you lot can too. At the terminate of this commodity you'll:
- empathise what an index is
- understand the types of indices and their differences
- empathize how the indices piece of work
- know in which situations to apply which type of index
Note that in this article we're using SQL Server, but the principle apply to many other relational databases like Postgres and MySQL eastward.k. The syntax might differ though. Let code!
Setup
For illustrating the code in this article I've created a table that a lot of applications utilize. It holds 20 milion records of User data and tin can be used to register new users, cheque passwords when logging in and changing user data. I've generated the table with Python, using the superfast insertion method described in this article. The lawmaking for creating the table looks similar this:
CREATE Tabular array [dbo].[Users] (
[Created] DATETIME Non NULL DEFAULT GETUTCDATE()
, [Modified] DATETIME Non NULL DEFAULT GETUTCDATE()
, [FirstName] NVARCHAR(100) NOT NULL
, [LastName] NVARCHAR(100) Not Cypher
, [UserName] NVARCHAR(100) NOT NULL
, [Password] NVARCHAR(100) NOT Nada
, [Age] INT NULL
); 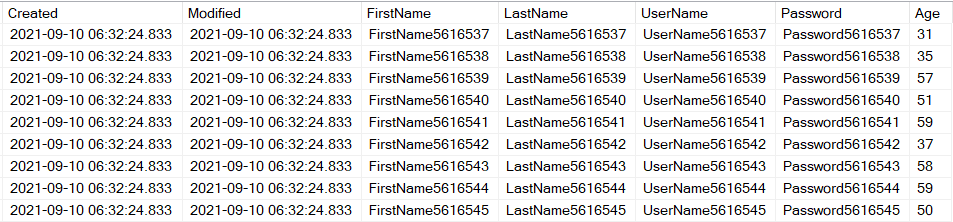
As you tin can run into it contains some columns that chronicle to the user (the terminal 5) and two columns that continue track of when the record is created and updated. This table has some problems which nosotros're going to solve in this commodity.
Imagine that our Users table is used for a website like Reddit. On every login we need to check whether the username and password. Besides, sometimes users alter their e-mail, username or password and then we need to update as well. In addition we need to exist able to add new users by inserting new records. How can nosotros perform fast queries in such a big table?
The heap
We've currently designed our table in the dumbest and slowest way possible. When we are looking for a particular user our table has to take a look at every record in the tabular array. This kind of tabular array is called a Heap Tabular array and examining each record in the table is chosen a Table Scan. Imagine going to a hotel and checking each single room before determining which 1 is yours! Very inefficient.
Querying
Let'due south try to find records by the LastName column:
SELECT *
FROM Med.dbo.UsersHeap WITH (NOLOCK)
WHERE LastName = 'LastName123123' Executing the query above will take quite some time; the database engine has to scan every tape in the table. It cannot finish at the showtime-constitute record because there might be even more user with the aforementioned terminal name. Also the data is unordered so the record tin be in any position (in any row number that is).
Let's analyze the execution programme:
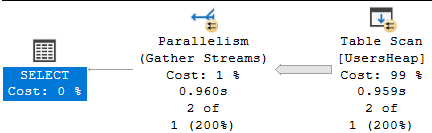
You'll see that the database engine performs a table browse which took almost a second! When yous hover your mouse on this right-most cake information technology shows you the prototype below:
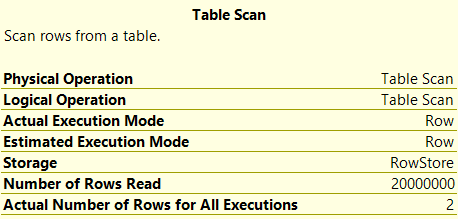
You lot'll see that it actually read all 20 million records and returned merely ii. These kinds of Heap tables and table scans are very inefficient and should not exist used. Nosotros can improve a lot by adding an index.
Amassed alphabetize
Allow'southward add together a clustered alphabetize to our tabular array: we'll add together a new cavalcade to our table that stores our primary key; an integer with a unique value for each row. These values are so sorted and stored physically, in a tree-like structure.
How it works
Just how does the database engine apply this alphabetize to recall rows quicker? Let's employ the hotel-example again: You need to find room E512.
- The letter Due east indicates that you accept to go to the east-wing of the hotel
- The first number (5) indicates that nosotros have to become to the 5th floor
- Once we exit the elevator nosotros run into a sign that says that rooms i–20 are on the left, and rooms 21–40 are on the right. Since the rooms are ordered we don't demand to look far when finding our room!
The database engine works a lot like this. Instead of visiting each single room in the hotel and checking whether it's ours, we use the tree-like structure of the index that leads u.s.a. to our destination much quicker. The but deviation is that instead of the three branches that nosotros use (the e-fly, 5th floor, right side of the hall), the database engine uses many, many more.
Creating the index
Permit's ready our table:
CREATE Tabular array [dbo].[Users] (
[Id] INTEGER IDENTITY Main Fundamental NOT Nothing
, [Created] DATETIME Not Zilch DEFAULT GETUTCDATE()
, [Modified] DATETIME Non Aught DEFAULT GETUTCDATE()
, [FirstName] NVARCHAR(100) NOT NULL
, [LastName] NVARCHAR(100) NOT NULL
, [UserName] NVARCHAR(100) Non Zippo
, [Countersign] NVARCHAR(100) Non Zilch
, [Age] INT NULL
); The magic is in the second line; when y'all provide a Main KEY column the database engine creates a clustered index automatically. The IDENTITY part will generate a new integer for every record. Our Id column is new. THe new table looks like this:
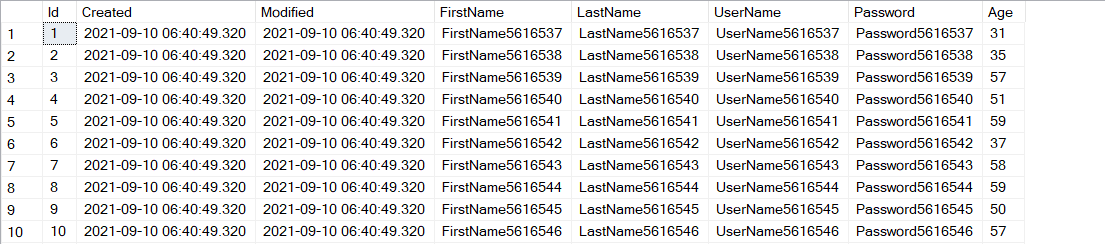
Querying
Now we tin retrieve records by the Id cavalcade. Let's say nosotros want to call up records of Id = 42:
SELECT *
FROM Med.dbo.Users WITH (NOLOCK)
WHERE Id = 42 When we execute this, the database engine uses our newly created index; it is much, much faster since information technology uses the hotel-similar method. We can also see this in the execution plan:
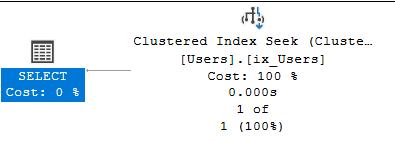
See that we're using a clustered index seek? This indicates that we're using our amassed index. Observe the time too: 0.000 seconds; that'southward fast! We can as well check this out in the execution details of this tile:
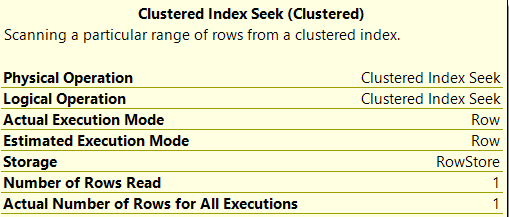
Meet that we've only read one single row? This is quite the difference compared to our table scan! Just what if we desire to employ another column to filter on?
Nonclustered index
Okay, so the chief central is on the Id column and nosotros can find our records pretty fast using the clustered index. How can we optimize queries where nosotros filter on other columns? For these columns we can create a nonclustered alphabetize.
How it works
A nonclustered alphabetize works much like the index in a book. These comprise certain words and where these words are used. In a economics book you might see that the term 'inflation' is used on page 42, 119 and 246. A nonclusted alphabetize works a lot like this: it takes all values from the column equally keys and registers all the corresponding id's (from the clustered index). A nonclustered index needs a amassed index to operate. These keys-values-pairs are ordered and stored in a tree-likes structure of their own and so we tin can apace locate them. This operation is chosen an Index Scan.
Offset we'll create the index:
CREATE NONCLUSTERED Index ix_users_lastname
ON Med.dbo.Users(LastName) Image you're filtering on LastName = 'Cartman':
- And then the nonclustered index will perform a key lookup: it will go through the tree, looking for the fundamental called 'Cartman'. It will observe iii records in our table that accept this final name; they have id'southward iv, 16 and 333.
- In footstep ii nosotros'll apply our clustered index, performing an index seek, to return our actual records. Permit'southward see this in action!
Querying
At present we tin recall records past the Name column. Let's say we want to call up records of LastName = 'LastName456456':
SELECT *
FROM Med.dbo.Users WITH (NOLOCK)
WHERE LastName = 'LastName456456' This query is superfast as well; as you tin can see in the execution program below all operations finished in 0.000 seconds:

You'll come across that it commencement executes the primal lookup; it looks for the value of our column and returns the id's. Then these id's get used in the alphabetize seek. These two indices working together guarantee a user-friendly, superfast query!
Source: https://towardsdatascience.com/sql-understand-how-indices-work-under-the-hood-to-speed-up-your-queries-a7f07eef4080
0 Response to "Speed Up Read Queries on a Non Indexed Table"
Post a Comment